Đầu tháng 10 này Facebook cho biết họ vừa đệ đơn kiện 2 công ty tại Mỹ về tội đã sử dụng phương pháp cạo (scraping) trên website để tham gia vào hoạt động thu thập dữ liệu quốc tế.
Đầu tháng 10 này Facebook cho biết họ vừa đệ đơn kiện 2 công ty tại Mỹ về tội đã sử dụng phương pháp cạo (scraping) trên website để tham gia vào hoạt động thu thập dữ liệu quốc tế.
 |
| Web scraping là quá trình lấy dữ liệu không có cấu trúc từ các trang web để kết xuất thành dữ liệu có cấu trúc |
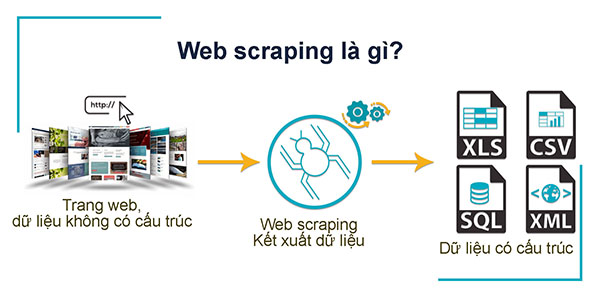
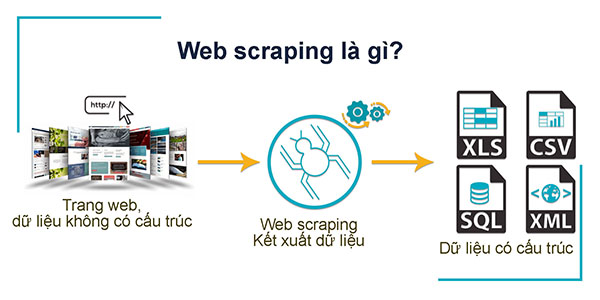
* Thế nào là web scraping?
Web scraping hay data scraping là một thuật ngữ công nghệ thường được giới chuyên môn ở Việt Nam dịch là “quét dữ liệu” từ các trang web, tuy nhiên nếu dịch sát nghĩa hơn và cũng mô tả đúng bản chất công việc hơn là “cạo dữ liệu” từ các trang web.
Web scraping là công việc trích xuất dữ liệu từ một trang web, thông tin này được thu thập và sau đó xuất thành định dạng hữu ích hơn cho người dùng (như một bảng tính chẳng hạn).
Ví dụ: Bạn định mua một smart phone trong tầm giá 7-10 triệu đồng. Vậy bây giờ điều bạn cần làm là tìm xem có những model nào trong tầm giá đó và mỗi model này được bán với giá bao nhiêu ở những cửa hàng khác nhau. Bạn sẽ vào từng trang web của từng cửa hàng tìm hiểu những thông tin cần thiết. Bởi vì mỗi trang web lại có một cấu trúc khác nhau và bên cạnh thông tin chính là tên model và giá cả còn có vô số thông tin khác như: mô tả, hình ảnh và nhận xét chẳng hạn, trong khi dữ liệu mà bạn cần chỉ là tên model và giá mà thôi. Bạn sẽ muốn bóc ra/cạo ra chỉ riêng thông tin cần thiết trên từng website và đặt những thông tin ấy trên cùng một bảng để tiện so sánh. Quá trình ấy gọi là web scraping.
* Web scraping được thực hiện như thế nào?
Trong ví dụ trên, web scraping được thực hiện bằng phương pháp thủ công với mục đích tương đối lành mạnh. Tuy nhiên trên thực tế web scraping thường được thực hiện tự động và với những mục đích không phải lúc nào cũng lành mạnh.
Để thực hiện web scraping, người ta viết ra những ứng dụng nhỏ, gọi là web scraper. Nguyên lý hoạt động của web scraper khá đơn giản, nó đọc code của trang web và trả về dữ liệu theo yêu cầu của người dùng web scraper. Thế nhưng vì kết cấu của mỗi trang web là mỗi khác nên nhiệm vụ này trở thành phức tạp.
Đầu tiên, web scraper sẽ được cung cấp một hoặc nhiều URL (địa chỉ web) để load trước khi trích xuất dữ liệu. Sau đó, scraper sẽ load toàn bộ code HTML cho trang đang đề cập. Những scraper cao cấp hơn sẽ kết xuất toàn bộ trang web, bao gồm các yếu tố CSS và Javascript. Sau đó, scraper sẽ trích xuất tất cả dữ liệu trên trang hoặc dữ liệu cụ thể được người dùng chọn trước khi chạy ứng dụng này. Hầu hết các web scraper sẽ xuất dữ liệu sang bảng tính CSV hoặc Excel, trong khi các scraper cao cấp hơn sẽ hỗ trợ các định dạng khác.
Một dạng scraping nâng cao hơn đó là database scraping (cạo cơ sở dữ liệu). Nó khá giống với web scraping, nhưng nếu web scraping chỉ lấy những thông tin thể hiện trên trang web thì tin tặc tạo ra bot (robot mạng) tương tác với phần ứng dụng nhằm lấy dữ liệu từ cơ sở dữ liệu của trang đó. Ví dụ như vào website của một công ty và lấy ra danh sách khách hàng của công ty đó (danh sách này vốn chứa trong website nhưng không hiện ra cho người dùng thông thường).
* Mục đích của web scraping là gì?
Dữ liệu trên một trang web thường do chủ trang web tốn rất nhiều công sức để nhập liệu. Lấy ví dụ một cửa hàng điện máy phải tốn rất nhiều công để nhập vào các mặt hàng, đặc tính kỹ thuật, đơn giá… Thế nhưng chỉ với một web scraper, đối thủ cạnh tranh có thể thu thập toàn bộ giá cả đó và làm giá cho mình thấp hơn một chút vừa đủ để khách hàng từ bỏ cửa hàng ấy mà quay sang mua hàng ở đối thủ cạnh tranh. Hình ảnh dưới đây mô tả việc web scraper lấy dữ liệu giá cả từ một cửa hiệu cho thuê xe ô tô để làm giá cạnh tranh.
Điều đáng nói là trong đa số trường hợp, việc làm này không bị xem là đánh cắp dữ liệu. Bởi vì đằng nào những thông tin này (giá hàng hóa, giá dịch vụ…) cũng công khai cho khách hàng biết để mua hàng. Điểm khác nhau là khách hàng xem từng trang để chọn đúng loại dịch vụ mình cần sử dụng, còn đối thủ cạnh tranh thì dùng web scraper để tự động thu thập một cách nhanh chóng toàn bộ dữ liệu nhằm phục vụ cho việc cạnh tranh của mình.
 |
| Đối thủ dùng web scraping để lấy dữ liệu từ website của XYZ và làm giá của mình thấp hơn một chút |
Điều này gây khó chịu cho chủ trang web bị scrape. Vì vậy đối với một số trang web lớn, người ta có thể lập trình web để phát hiện và ngăn chặn web scraping. Ở một số quốc gia, có hẳn những điều luật để phạt hành vi scrape.
Ở chiều ngược lại không phải mọi động tác web scraping đều xấu. Trong nhiều trường hợp, chủ dữ liệu muốn truyền tải dữ liệu đến càng nhiều người càng tốt. Ví dụ website của nhiều chính phủ cung cấp dữ liệu cho các website công cộng. Tương tự đối với các trang về du lịch, đặt vé hay đặt phòng khách sạn. Các con bot lấy dữ liệu, phân loại nội dung rồi đưa dữ liệu ấy đến website của mình. Điều này giúp dữ liệu của các công ty du lịch ấy đến với khách hàng được nhiều hơn.
* Mạng xã hội - “kho vàng” cho web scraping
Trở lại vụ kiện của Facebook.
Mỗi thành viên Facebook nói riêng và mạng xã hội nói chung đều cung cấp các thông tin cá nhân của mình trên đó. Bạn có thể biết được thông tin của bạn bè mình thông qua đó. Bạn cũng có thể biết thông tin của những người khác nếu họ công khai dữ liệu về mình. Điều này không vi phạm điều luật nào cả vì số đối tượng mà bạn biết đến không nhiều và bạn không sử dụng những thông tin đó cho những mục tiêu lợi ích riêng. Tuy nhiên, nếu có ai đó dùng web scraper để thu thập toàn bộ thông tin về tất cả người dùng Facebook ở Đồng Nai chẳng hạn, để từ đó tìm ra thị hiếu, sở thích… người dùng Đồng Nai và bán dữ liệu đó cho các công ty tiếp thị thì vấn đề lại khác.
Facebook cho biết họ đã đệ đơn kiện ở Mỹ chống lại hai công ty đã sử dụng web scraping để tham gia vào hoạt động thu thập dữ liệu quốc tế. Các công ty này đã thu thập dữ liệu từ Facebook, Instagram, Twitter, YouTube, LinkedIn và Amazon, để bán “thông tin tiếp thị” và các dịch vụ khác. Hai công ty này là BrandTotal Ltd., có trụ sở tại Israel và Unimania Inc., được thành lập tại Delaware. Việc làm của hai công ty này đã vi phạm Điều khoản dịch vụ của Facebook và Facebook cho biết đang theo đuổi hành động pháp lý để bảo vệ người dùng của mình.
Là một trang web lớn, Facebook có các biện pháp bảo vệ chống scraping, thế nhưng các công ty này đã né tránh các biện pháp này bằng một thủ thuật. Họ thông qua bộ tiện ích mở rộng dùng cho trình duyệt có tên là UpVoice và Ads Feed. Khi mọi người đã cài đặt những tiện ích mở rộng này cho trình duyệt và từ trình duyệt đó truy cập Facebook thì nó sẽ tự động truy cập và thu thập dữ liệu. Tiện ích này sử dụng các chương trình tự động để scrape tên, ID người dùng, giới tính, ngày sinh, tình trạng mối quan hệ, thông tin vị trí và các thông tin khác liên quan đến tài khoản của họ, sau đó nó gửi dữ liệu cóp nhặt được đến máy chủ của BrandTotal và Unimania.
Facebook cho biết trường hợp này là ví dụ mới nhất về các hành động của họ nhằm phá vỡ và cưỡng chế đối với các công ty lấy cắp dữ liệu người dùng, cũng như những người thúc đẩy các công ty ấy hành động phi pháp.
Phạm Hoài Nhân
![[Infographic] 10 xã sắp thành lập phường của Đồng Nai có quy mô dân số, diện tích ra sao?](/file/e7837c02876411cd0187645a2551379f/032026/thumbnail_10_xa_len_phuong_20260325220604.jpg?width=400&height=-&type=resize)



![[Infographic] Trình tự lấy ý kiến nhân dân đối với Đề án thành lập các phường và thành lập thành phố Đồng Nai trực thuộc Trung ương](/file/e7837c02876411cd0187645a2551379f/032026/anh_thumbnail_trinh_tu_lay_y_kien_20260325094852.jpg?width=400&height=-&type=resize)








