
Khi bạn mở Facebook, trên trang chính của bạn (gọi là trang Bảng tin hay News Feed) sẽ xuất hiện một số bài đăng từ bạn bè, các trang yêu thích và cả quảng cáo nữa. Những bài đăng này được Facebook tuyển chọn từ hàng tỷ bài đăng đang có mà Facebook cho rằng bạn muốn xem. Vậy Facebook tuyển chọn như thế nào?
Khi bạn mở Facebook, trên trang chính của bạn (gọi là trang Bảng tin hay News Feed) sẽ xuất hiện một số bài đăng từ bạn bè, các trang yêu thích và cả quảng cáo nữa. Những bài đăng này được Facebook tuyển chọn từ hàng tỷ bài đăng đang có mà Facebook cho rằng bạn muốn xem. Vậy Facebook tuyển chọn như thế nào? Dưới đây là một số nguyên tắc do chuyên gia của Facebook tiết lộ.
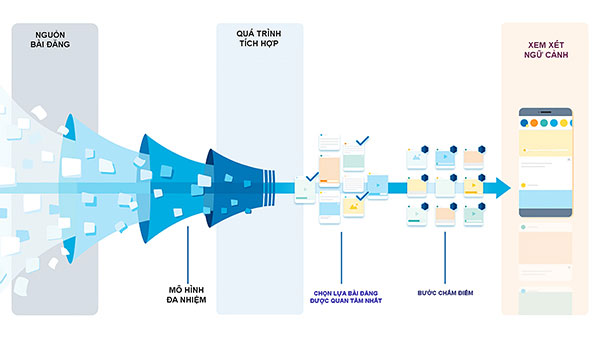 |
| Sơ đồ xử lý thông tin trước khi đưa lên bảng tin. Nguồn: Facebook. Chuyển ngữ: PHN |
* Facebook sử dụng AI để chọn lựa các bài đăng xuất hiện trên bảng tin của mỗi người
Khi nói đến News Feed, hầu hết mọi người đều hiểu rằng những bài đăng trên đó đều tuân theo một thuật toán đang hoạt động chứ không phải xuất hiện ngẫu nhiên. Facebook đã sử dụng đến trí tuệ nhân tạo (AI) và hệ thống xếp hạng máy học (machine learning, ML) cung cấp cho News Feed là cực kỳ phức tạp, với nhiều lớp. Trên newsroom của Facebook mới đây, 3 chuyên gia của Facebook là Akos Lada, Giám đốc Khoa học dữ liệu, Meihong Wang, Giám đốc Kỹ thuật và Tak Yan, Giám đốc Quản lý sản phẩm đã chia sẻ những thông tin chi tiết mới về cách hệ thống xếp hạng này hoạt động và những thách thức trong việc xây dựng một hệ thống để cá nhân hóa nội dung cho hơn 2 tỷ người và hiển thị cho mỗi người trong số họ những nội dung phù hợp và có ý nghĩa đối với họ mỗi khi họ truy cập Facebook.
* Điều này có gì khó?
Đầu tiên, khối lượng rất lớn. Hơn 2 tỷ người trên thế giới sử dụng Facebook. Trung bình mỗi người trong số đó có hơn 1 ngàn bài đăng “ứng cử viên” (tức bài đăng có khả năng xuất hiện trong bảng tin của người khác). Đối với mỗi người trên Facebook, có hàng ngàn tín hiệu mà Facebook cần đánh giá để xác định những gì người đó có thể thấy phù hợp nhất. Vì vậy, Facebook có hàng ngàn tỷ bài đăng và hàng ngàn tín hiệu, và nó cần phải xem xét để dự đoán những gì mà mỗi người trong chúng ta muốn xem trên bảng tin của mình ngay lập tức. Khi bạn mở Facebook, quá trình đó diễn ra ở chế độ nền chỉ trong giây lát để tải Bảng tin của bạn.
Một khi đã làm được tất cả những điều này, vẫn chưa đủ và Facebook cần tính đến các vấn đề mới nảy sinh, chẳng hạn như dụ dỗ để lừa đảo và sự lan truyền của thông tin giả. Khi điều này xảy ra, Facebook cần tìm ra các giải pháp mới. Trên thực tế, hệ thống xếp hạng không chỉ là một thuật toán duy nhất; đó là nhiều lớp mô hình ML và bảng xếp hạng mà Facebook áp dụng để dự đoán nội dung phù hợp và có ý nghĩa nhất đối với từng người dùng. Khi chuyển qua từng giai đoạn, hệ thống xếp hạng sẽ thu hẹp hàng ngàn bài đăng ứng viên đó xuống còn vài trăm bài xuất hiện trong bảng tin của ai đó tại bất kỳ thời điểm nào.
* Nó hoạt động như thế nào?
Nói một cách đơn giản, hệ thống xác định bài đăng nào hiển thị trong bảng tin của bạn và theo thứ tự nào, bằng cách dự đoán những gì bạn có khả năng quan tâm hoặc tương tác cao nhất. Những dự đoán này dựa trên nhiều yếu tố, bao gồm những gì và những người bạn đã theo dõi, thích hoặc tương tác gần đây. Để hiểu cách thức hoạt động của điều này trong thực tế, hãy bắt đầu với những gì xảy ra với một người đăng nhập vào Facebook: Ta hãy gọi anh ta là Juan.
 |
| Facebook tiến hành chấm điểm cho từng bài đăng và ưu tiên xuất hiện trên bảng tin những bài đăng có điểm cao nhất. Nguồn: Ảnh chụp màn hình video của Facebook |
Kể từ khi Juan đăng nhập vào ngày hôm qua, người bạn Wei của anh ấy đã đăng một bức ảnh về con gà trống chọi của anh ấy. Một người bạn khác, Saanvi, đã đăng một đoạn video về buổi chạy bộ buổi sáng của cô ấy. Trang yêu thích của anh ấy đã xuất bản một bài báo thú vị về cách tốt nhất để xem dải ngân hà vào ban đêm, trong khi nhóm nấu ăn yêu thích của anh ấy đăng bốn công thức nấu bột chua mới.
Tất cả nội dung này có thể liên quan hoặc thú vị đối với Juan vì anh đã chọn theo dõi những người hoặc trang chia sẻ nội dung đó. Để quyết định nội dung nào trong số này sẽ xuất hiện cao hơn trong bảng tin của Juan, Facebook cần dự đoán nội dung nào quan trọng nhất với anh ấy và nội dung nào mang giá trị cao nhất đối với anh ấy.
Facebook sử dụng các đặc điểm của một bài đăng, chẳng hạn như ai được gắn thẻ trong ảnh và thời điểm nó được đăng, để dự đoán liệu Juan có thích nó hay không. Ví dụ: nếu Juan có xu hướng tương tác với các bài đăng của Saanvi (chia sẻ hoặc bình luận) thường xuyên và video đang chạy của cô ấy rất gần đây, thì khả năng cao là Juan sẽ thích bài đăng của cô ấy. Nếu trước đây Juan tương tác với nhiều nội dung video hơn ảnh, thì dự đoán tương tự đối với bức ảnh của Wei về chú chó đuôi dài của anh ta có thể khá thấp. Trong trường hợp này, thuật toán xếp hạng của Facebook sẽ xếp hạng video đang chạy của Saanvi cao hơn ảnh con chó của Wei vì nó dự đoán xác suất cao hơn rằng Juan sẽ thích nó.
Nhưng thích không phải là cách duy nhất mọi người thể hiện sở thích của mình trên Facebook. Mỗi ngày, mọi người chia sẻ các bài viết mà họ thấy thú vị, xem video của những người bạn hoặc những người nổi tiếng mà họ theo dõi hoặc để lại nhận xét sâu sắc về bài đăng của bạn bè họ. Nhiều mô hình ML tạo ra nhiều dự đoán cho Juan: xác suất anh ấy sẽ tương tác với ảnh của Wei, video của Saanvi, bài báo về dải ngân hà hoặc công thức bột chua. Mỗi mô hình cố gắng xếp hạng các phần nội dung này cho Juan. Đôi khi họ không đồng ý - có thể có khả năng cao là Juan thích video chạy của Saanvi hơn là bài báo về dải ngân hà, nhưng có khả năng anh ấy sẽ nhận xét về bài báo hơn là video. Vì vậy, cần một cách để kết hợp những dự đoán khác nhau này thành một điểm số được tối ưu hóa cho mục tiêu chính của chúng tôi là giá trị lâu dài.
Làm thế nào đo lường liệu điều gì đó có tạo ra giá trị lâu dài cho một người hay không? Điều này được thực hiện thông qua các khảo sát của Facebook.
* Bóc tách các lớp
Để xếp hạng hơn 1 ngàn bài đăng trên mỗi người dùng, mỗi ngày, cho hơn 2 tỷ người - trong thời gian thực cần làm cho quy trình hiệu quả. Facebook quản lý điều này theo nhiều bước khác nhau, được sắp xếp một cách chiến lược để làm cho nó nhanh chóng và hạn chế số lượng tài nguyên máy tính cần thiết.
Đầu tiên, hệ thống thu thập tất cả các bài đăng ứng cử viên mà Facebook có thể xếp hạng cho Juan. Chúng bao gồm bất kỳ bài đăng nào được chia sẻ với Juan bởi một người bạn, nhóm hoặc trang mà anh ấy kết nối được thực hiện kể từ lần đăng nhập cuối cùng và chưa bị xóa. Nhưng còn các bài đăng được tạo trước lần đăng nhập cuối cùng của Juan mà anh ấy chưa thấy thì sao?
Các bài đăng mới được xếp hạng cho Juan (nhưng không được anh ấy nhìn thấy) trong các phiên trước của mình được thêm vào trong bảng tin phiên này. Ngoài ra, bất kỳ bài đăng nào mà Juan đã xem từ đó gây ra một cuộc trò chuyện thú vị giữa bạn bè của anh ấy cũng được thêm vào bảng tin phiên này.
Tiếp theo, hệ thống cần chấm điểm từng bài đăng đối với nhiều yếu tố. Để tính toán điều này cho hơn 1 ngàn bài đăng, cho mỗi người trong số hàng tỷ người dùng - tất cả đều theo thời gian thực - Facebook chạy các mô hình này cho tất cả các câu chuyện ứng viên song song trên nhiều máy, được gọi là máy dự đoán.
Thông qua nhiều phép toán chọn lọc khác nữa để rút lại số lượng bài đăng “ứng cử viên” từ hàng tỷ xuống còn vài trăm bài. Tất cả các bước xếp hạng này diễn ra trong thời gian Juan mở ứng dụng Facebook và trong vài giây, anh ấy có một bảng tin được chấm điểm sẵn sàng để duyệt và thưởng thức.
Phạm Hoài Nhân
(Theo Newsroom của Facebook)


![[Infographic] 4 điểm mới quan trọng của Luật sửa đổi, bổ sung một số điều của Luật Phòng, chống tham nhũng](/file/e7837c02876411cd0187645a2551379f/122025/90f92328a1122e4c7703_20251229131810.jpg?width=400&height=-&type=resize)


![[Chùm ảnh] Toàn cảnh Khu công nghiệp Biên Hòa 1 đang tháo dỡ nhà xưởng, bàn giao mặt bằng](/file/e7837c02876411cd0187645a2551379f/122025/anh_1_resized_20251230152415_20251230165401.jpg?width=500&height=-&type=resize)








